Hypothesis Testing when using the NHANES-CMS linked data
Purpose
The t-test and chi-square statistics are used to test statistical hypotheses about population parameters. This module will demonstrate the use of these statistics in NHANES data analysis.
Task 1: Use the t-test statistic
The t-test is used to test the null hypothesis that the means or proportions of two population subgroups are equal OR that the difference between two means or proportions equals zero when the estimates are based on a small probability sample. When using a simple random sample, small is defined as less than 30.
The t-test is used to test the null hypothesis that two population means or proportions, θ1 and θ2, are equal OR, equivalently, that the difference between two population means or proportions is zero. To test this hypothesis, assuming the covariance is small, as is the case with NHANES data, the following formula is used
Equation for t-Test Where Covariance is Small
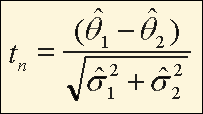 (1)
(1)
where,
![]() 1 is an estimate of θ1 based on a probability sample,
1 is an estimate of θ1 based on a probability sample,
![]() 1 is an estimate of the standard error of
1 is an estimate of the standard error of ![]() 1,
1,
![]() 2 is an estimate of θ2,
2 is an estimate of θ2,
and ![]() 2 is an estimate of the standard error of
2 is an estimate of the standard error of ![]() 2.
2.
In instances where the t statistic is based on a small number of independent pieces of information (i.e. a small number of degrees of freedom [<30]), the statistic given in equation 1 follows a Student’s t distribution with mean=0 and unit variance with n degrees of freedom. In the NHANES 1999-2002 sample, the degrees of freedom depend on the number of first stage units, or PSUs, containing observations and is defined as the number of PSUs minus the number of strata. (See Sample Design module for more information.)
The equality of means is usually tested at the .05 level of significance.
References:
Cochran, WG. Sampling Techniques. John Wiley & Sons. 1977.
Lohr SL. Sampling: Design and Analysis. Duxbury Press. Pacific Grove 1999.
In this task, you will use Stata commands to calculate a t-statistic and assess whether the mean systolic blood pressures (SBP) in males and females age 20 years and older are statistically different.
Step 1: Set Up Stata to Produce Means
Follow the steps in the summary table below to produce the mean SBP and the t-test to test whether the mean SBP between males and females obtained is statistically significant different using the Stata command svy:mean.
Warning: There are several things you should be aware of while analyzing NHANES data with Stata. Please see the Stata Tips page to review them before continuing.
Step 2: Use svyset to define survey design variables
Remember that you need to define the SVYSET before using the SVY series of commands. The general format of this command is below:
svyset [w=weightvar], psu(psuvar) strata(stratavar) vce(linearized)
To define the survey design variables for your SBP analysis, use the weight variable for 4 years of MEC data (wtmec4yr), the PSU variable (sdmvpsu), and strata variable (sdmvstra). The vce option specifies the method for calculating the variance and the default is “linearized” which is Taylor linearization. Here is the svyset command for four years of MEC data:
svyset [w= wtmec4yr], psu(sdmvpsu) strata(sdmvstra) vce(linearized)
Step 3: Use svy:mean to generate means and standard errors in Stata
Now, that the svyset has been defined you can use the Stata command, svy: mean, to generate means and standard errors. The general command for obtaining weighted means and standard errors of a subpopulation is below.
svy: mean varname, subpop(if condition)
Use the svy : mean command with the systolic blood pressure variable (bpxsar) to estimate the mean systolic blood pressure for people age 20 years and older. Use the subpop( ) option to select a subpopulation for analysis, rather than select the study population in the Stata program while preparing the data file. This example uses an if statement to define the subpopulation based on the age variable’s (ridageyr) value. Another option is to create a dichotomous variable where the subpopulation of interest is assigned a value of 1, and everyone else is assigned a value of 0.
svy: mean bpxsar, subpop(if ridageyr>=20 & ridageyr<.)
Output of svy:mean

Step 4: Use over option of svy:mean command to generate means and standard errors for different subgroups in Stata
You can also add the over() option to the svy:mean command to generate the means for different subgroups. When you do this, you can type a second command, estat size, to have the output display the subgroup observation numbers. Here is the general format of these commands for this example:
svy: mean varname, subpop(if condition) over(var1 var2)
estat size
Use the svy : mean command with the systolic blood pressure variable (bpxsar) to estimate the mean systolic blood pressure for people age 20 years and older. Use the subpop( ) option to select a subpopulation for analysis, rather than select the study population in the Stata program while preparing the data file. This example uses an if statement to define the subpopulation based on the age variable’s (ridageyr) value. Another option is to create a dichotomous variable where the subpopulation of interest is assigned a value of 1, and everyone else is assigned a value of 0. Use the over option to get stratified results. This example produces estimates by gender. Use the estate size post estimation command to display the number of subpopulation observations and weighted numbers.
svy: mean bpxsar, subpop(if ridageyr>=20 & ridageyr<.) over(riagendr)
estat size, obs size
Output of svy:mean with over option

Step 5a: Test the hypothesis using the lincom post estimation command
If you have already done some estimations, then you can use the lincom command to test the hypothesis that the difference between the mean for the subpopulations equal 0. Use square brackets around the variable you are estimating. After the variables in square brackets, put the stratifier that you want to test (e.g. the variable in the over option). If you used labels for the variable, you can use labels instead of the coded values. Here is the general format of these commands for this example:
lincom [varname]stratval1 – [varname]stratval2
Because you have done some prior estimation, you can use the lincom post estimation command to test the hypothesis that the difference between mean SBP (bpxsar) for males and females equal 0. This example uses labeled values (male, female) instead of the coded values (1,2) for the gender variable (riagendr).
lincom [bpxsar]male – [bpxsar]female
Output of lincom post estimation command

Step 5b: Test the hypothesis using svy:reg command
The svy:reg command could also be used to calculate the t-statistic. The difference between using svy:reg and lincom is that svy:reg can be used without prior estimation. The xi prefix is used before the command to denote a categorical variable and the i prefix before categorical variables. Here is the general format of these commands for this example:
xi: svy, subpop(if condition): reg dependentvar i.varname
Use the svy:reg command with the xi prefix to calculate the t-statistic and assess whether the mean SBP (bpxsar) for males and females age 20 years and older are statistically different. The i prefix denotes the categorical variable, which in this example is riagendr. Use the char function choose the reference group for the categorical variable.
char riagendr[omit]2
xi:svy, subpop(if ridageyr.=20 & ridageyr<.):reg bpxsar i.riagendr,
Output of svy:reg command

Step 6: Review Stata means and t-test output
Here a table summarizing the results of the previous analyses:
| Variable | Subpopulation analyzed | Number of respondents with data | Mean | p value |
|---|---|---|---|---|
| Systolic blood pressure | Adults age 20 and older | 9,056 | 123 | n/a |
| Men age 20 and older | 4,301 | 124 | 0.0132(men vs. women) | |
| Women age 20 and older | 4,755 | 122 |
According to the stratified analysis, men’s mean blood pressure is 2 points higher than women’s. This difference is statistically significant (i.e. a difference this big or bigger would happen just by chance (in a sample of this size) only 1.3% of the time). 9,056 respondents had information on systolic blood pressure (SBP).
Task 2: Perform chi-square test
The chi-square test is used to test the association between two variables cross-classified in a two-way table and the homogeneity of their association.
The chi-square test is used to test the independence of two variables cross classified in a two-way table. (A chi-square statistic with n degrees of freedom is based on a statistic equal to the sum of the squares of n independent normally distributed random variables with mean=0 and unit variance.)
For example, suppose we wished to test the hypothesis that blood pressure cuff size is independent of gender and that we have the following observed frequencies obtained as a result of the cross-classification of blood pressure cuff sizes and gender.
| 1 | 2 | 3 | 4 | Cumulative | |
|---|---|---|---|---|---|
| Men | 63 | 1387 | 2409 | 453 | 4312 |
| Women | 222 | 2065 | 2002 | 493 | 4782 |
| Both genders | 285 | 3452 | 4411 | 946 | 9094 |
In a simple random sample setting (unweighted data), the expected cell frequencies under the null hypothesis that blood pressure cuff size and gender are independent could be obtained by multiplying the marginal total for the jth column by the proportion of individuals in the ith row.
For example, the expected value of blood pressure cuff size 1 for men would be 285*(4312/9094)=135; the expected value of blood pressure cuff size 4 for women would be 946*(4782/9094)=497.
Thus, if Oij = the observed frequency of the ith row and jth column, where i=1,2, … i and j=1,2, … j and
Eij = the expected frequency of the ith row and jth column
Then the formula to test the null hypothesis of independence, using the chi-square statistic, would be
Equation to Test the Null Hypothesis
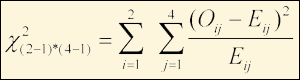 (1)
(1)
This statistic has degrees of freedom equal to the number of rows minus 1, multiplied by the number of columns minus 1.
In a complex sample setting, you would use a statistic similar to equation (1) above, modified to account for survey design with degrees of freedom equal to the number of PSUs minus the number of strata containing observations. This statistic can be obtained through SAS proc surveyfreq (CHISQ, based on the Rao-Scott chi-square with an adjusted F statistic). The analogous procedure in SUDAAN version 9.0 (proc crosstab), provides limited chi-square statistics based on Wald chi-square and does not provide an F adjusted p-value. However, SUDAAN regression models do provide F adjusted chi-square statistics which are recommended for analyzing NHANES data.
The Cochran Mantel Haenzel Test, an extension of the Pearson Chi-Square, can be applied to stratified two-way tables to test for homogeneity or independence in a non-survey setting. For a complex sample its analogue can be obtained in SUDAAN proc crosstab (cmh).
References:
Agresti A. An Introduction to Categorical Data Analysis. Wiley Series in Probability and Statistics. 1996. New York.
In this task, you will use the chi-square test in Stata to determine whether gender and blood pressure cuff size are independent of each other. The chi-square statistics is requested from the Stata command svy:tabulate.
Warning: There are several things you should be aware of while analyzing NHANES data with Stata. Please see the Stata Tips page to review them before continuing.
Step 1: Use svyset to define survey design variables
Remember that you need to define the SVYSET before using the SVY series of commands. The general format of this command is below:
svyset [w=weightvar], psu(psuvar) strata(stratavar) vce(linearized)
To define the survey design variables for your blood pressure cuff size (bpacsz) analysis, use the weight variable for four-yours of MEC data (wtmec4yr), the PSU variable (sdmvpsu), and strata variable (sdmvstra) .The vce option specifies the method for calculating the variance and the default is “linearized” which is Taylor linearization. Here is the svyset command for four years of MEC data:
svyset [w= wtmec4yr], psu(sdmvpsu) strata(sdmvstra) vce(linearized)
Step 2: Regroup blood pressure cuff size variable
In this example, a new variable (cuff_size) is created to regroup blood pressure cuff size (bpacsz) from five categories to four categories. This collapses the infant (1) and child (2) groups. Use the gen command to create a new variable.
gen cuff_size=1 if bpacsz==1 | bpacsz==2
replace cuff_size=2 if bpacsz==3
replace cuff_size=3 if bpacsz==4
replace cuff_size=4 if bpacsz==5
Step 3: Generate chi-square statistics using svy:tabulate
Now, that the svyset has been defined you can use the Stata command, svy: tabulate, to produce two-way tabulations with tests of independence. Some of the options for the tab command include:
- column and row to display column and row percentages (if you do not specify this you will get cell proportions);
- obs lists the number of observations in each cell; count lists the weighted n in each cell and by adding format(%11.0fc) you will display the counts with commas rather than scientific notation;
- ci gives the confidence interval around each estimate, but can only be used with either row or column, not both; and
- the Pearson (Rao-Scott correction F-statistic) chi-square (pearson), null-based (null), and Wald (wald) test statistics.
The general command for generating two-way tabulations is below.
svy:tabulate varname, subpop(if condition) options
Use the svy : tabulate command to produce two-way tabulations for gender (riagendr) and blood pressure cuff size (cuff_size) with tests of independence for people age 20 years and older. (See Section 5.4 of Korn and Graubard Analysis of Data from Health Surveys, pp 207-211). Use the subpop( ) option to select a subpopulation for analysis, rather than select the study population in the Stata program while preparing the data file. This example uses an if statement to define the subpopulation based on the age variable’s (ridageyr) value. Another option is to create a dichotomous variable where the subpopulation of interest is assigned a value of 1, and everyone else is assigned a value of 0. The options specified for this example, use the column, rows, obs, percent, pearson, null and wald test statistic options.
svy:tab riagendr cuff_size, subpop (if ridageyr >=20 & ridageyr<.) column row obs percent pearson null wald
Output of svy:tabulate command with column, row, obs, percent, pearson, null and wald options

Step 4: Review output
Here is a table summarizing the output:
| Variable | Men age 20 and older (n=4312) |
Women age 20 and older (n=4782) |
p value |
|---|---|---|---|
| Cuff size | |||
| (1) Infant | 0% | 0% | <0.0001 |
| (2) Child | 1.5% | 5% | |
| 3 Adult | 29% | 44% | |
| 4 Large | 58% | 41% | |
| 5 Thigh | 12% | 10% |
Men have a larger cuff size than women – for example, 70% of men had cuff size of 4 or 5 compared to 51% of women. Cuff size varies significantly according to gender (p<0.0001). NOTE: The grayed cells have too few observations to create stable estimates and should probably not be reported.