
National, regional, state, and local data using interactive maps, trend lines, charts, and tables.
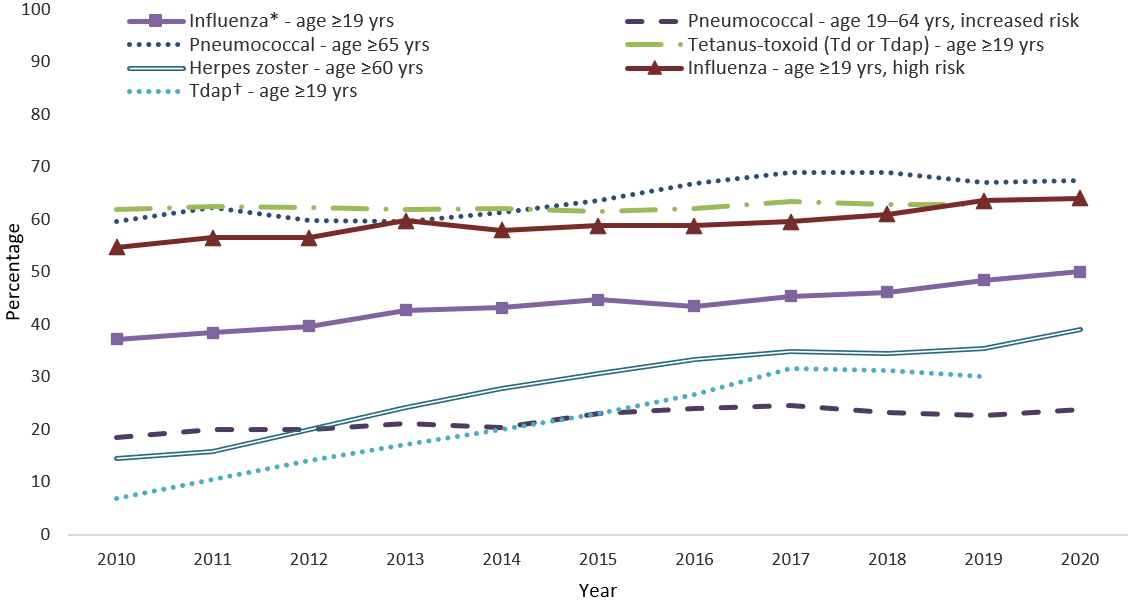
CDC annual reports and documents based on adult vaccination surveys and other data sources.
Estimates for adults who completed a Behavior Risk Factor Surveillance System interview.
Estimates for people who recently had a live birth and completed a PRAMS interview.
Estimates from the CMS Long-term Minimum Data Set for nursing home residents.