
The map gallery features maps that are being used to meet heart disease and stroke prevention progra
Easily download high quality maps of heart disease, stroke, and socioeconomic conditions.
Maps and graphs showing where heart disease and stroke death rates are changing.
Data presented through the widget automatically updates so the data presented on your page is accura
Featured
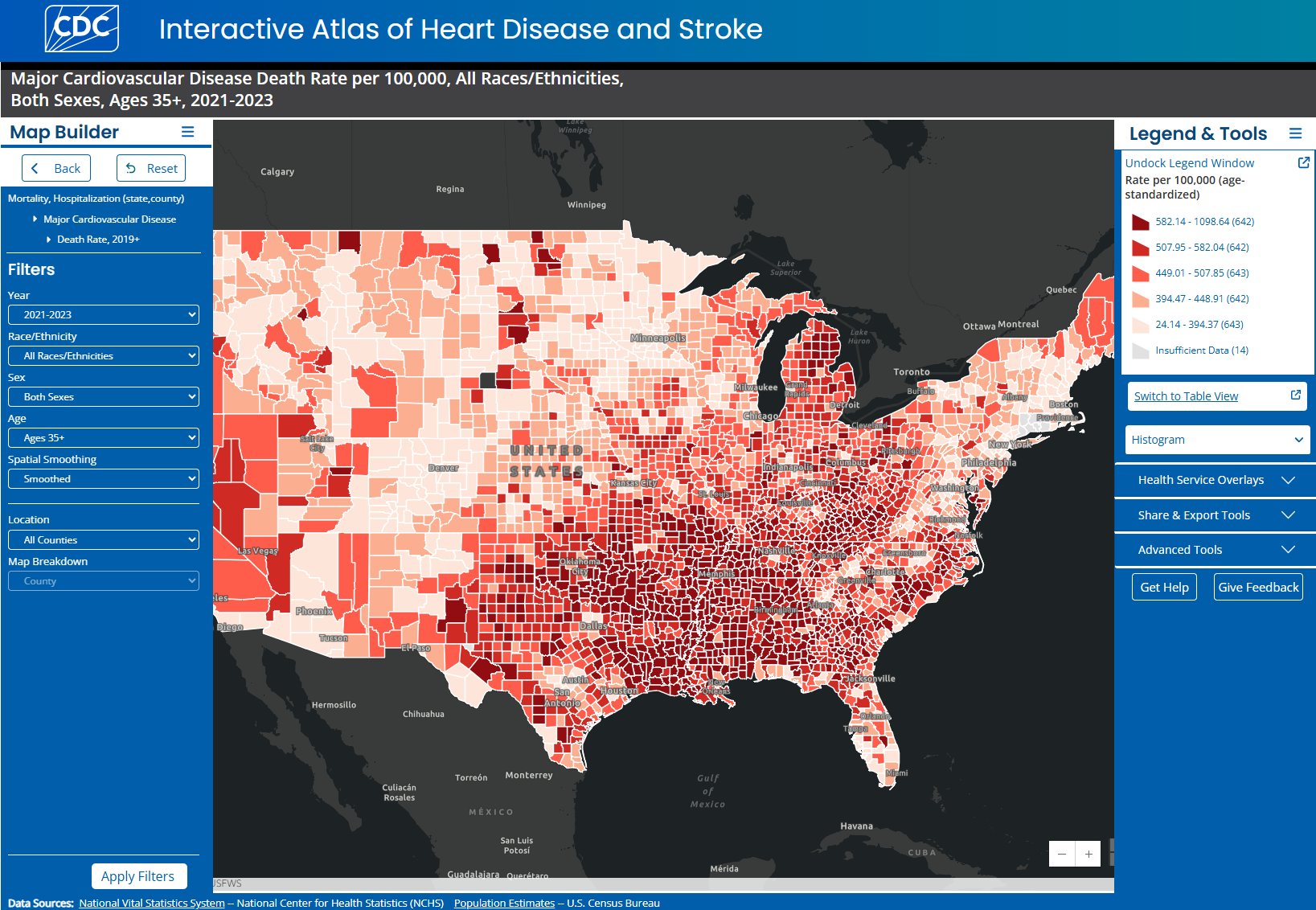
Create maps on heart disease and stroke, risk factors, and social determinants of health.

This project builds GIS capacity within state and local health departments for the surveillance and

The RST allows users to input their own data to generate local measures of chronic disease